Autonomous driving is a very simple task in theory, but still remains unsolved at large. How does openpilot tackle the problems that arise on the road?
Before we explore openpilot’s inner workings, let’s do a little thought experiment.
Our Very Own openpilot
Imagine we were designing very simple software for an autonomous vehicle. In order for it to react to the environment (other cars, a lane split), we need to be able to read sensor data, act on that data and update the actuators, such as the steering wheel or throttle.
From this description, we can derive a very simple abstract implementation of the core system functionality:
while (true) {
read sensor data
compute adjustments using machine-learning model
apply adjustments to actuators
}
While this may seem overly simplified, in essence this is how openpilot works internally. In reality, openpilot uses over 300 Python files divided into various submodules, dependencies and multiple hardware components to run this system.
This post aims to outline the main architectural components and processes along the path from sensor input to actuator output, their responsibilities, the design patterns applied within or between components and the trade-offs that were encountered in this architecture.
The Architecture
Now that we have a basic idea about how an autonomous system works, let’s see how openpilot actually does it.
We identified the main components of openpilot by analysing and running the source code from the GitHub repository and created a neat and tidy diagram from that analysis. Don’t worry if this diagram seems overwhelming, in the following sections we will try our best to explain what each component means and does. You, the reader, are encouraged to go back and forth between the text and this diagram to fully grasp openpilot’s inner workings.
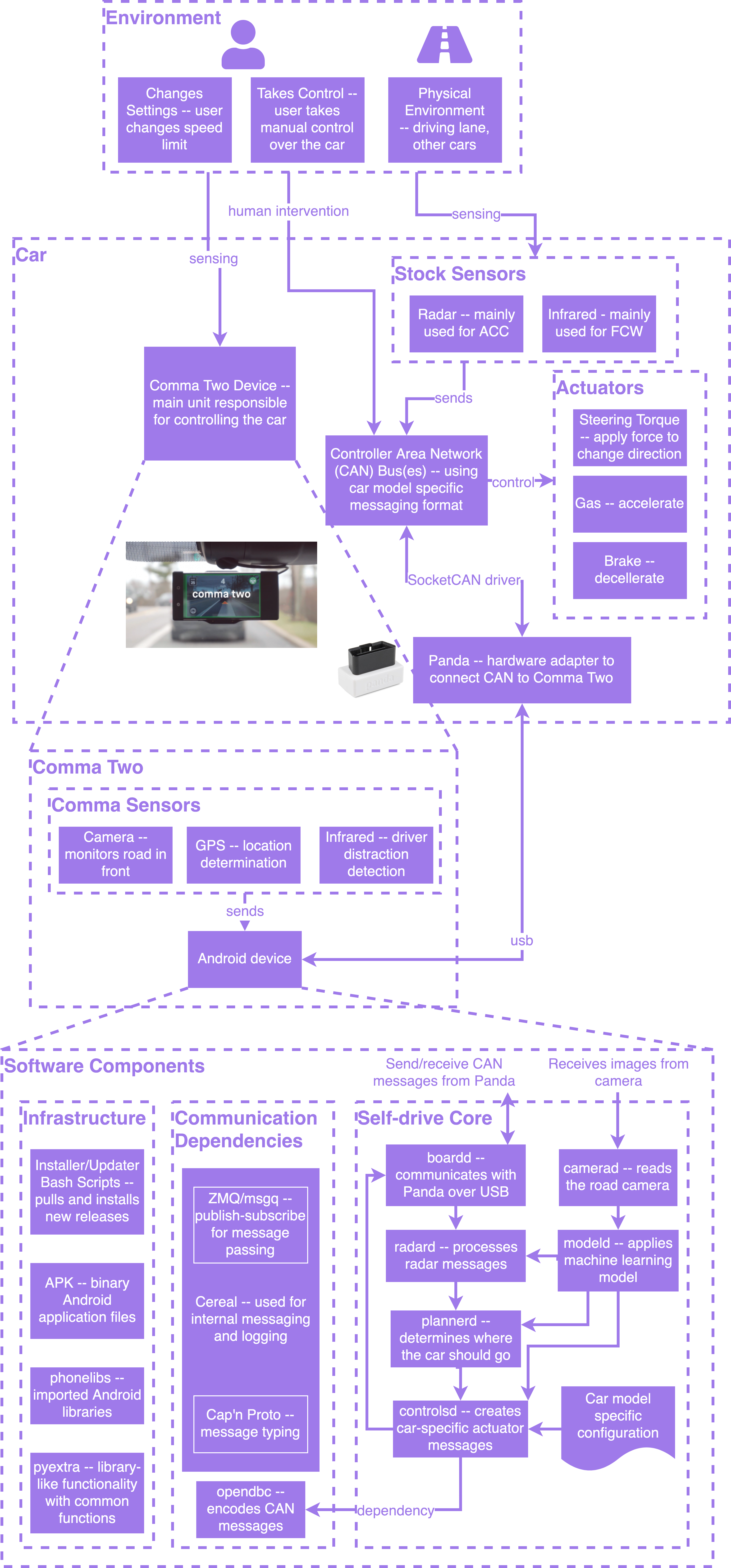
The architecture diagram is a combination of run-time and development view, since they are related and best explained together in this system. The logical view is not discussed because the system performs mostly a single task (control your car) and there is not much end-user functionality. The process/deployment view is also not discussed. This is because some parts of comma.ai’s deployment procedures and cloud infrastructure are not open source resulting in an incomplete analysis.
Multiple sensors observe the environment in and around the car. The stock sensors included by the manufacturer are a radar and an infrared sensor. The Comma Two delivers a front-facing camera, GPS, and an infrared driver distraction camera. These inputs are unified to deliver the desired functionality.
The diagram conveys another important architectural decision that the openpilot developers made: openpilot is not a single monolithic process but rather a coordinated cluster of processes. Being able to prioritize some processes over others gives openpilot the ability to adhere to the strict timing requirements necessary for autonomous driving.
We’re now going to untangle said processes in the bottom part of the diagram by analysing two scenarios:
- A car is braking in front of us
- The road is curving
In the following text, we will investigate these scenarios step by step, explaining what the software components are, their responsibilities, and how they communicate.
Scenario 1: Lead car brakes/slows down
Now consider a car in front of you that suddenly brakes. Your ACC-equipped car will notice this and its radar will send a message to the CAN bus. The CAN bus is continuously read by a hardware device of comma.ai’s making, called the panda.
The panda forwards this information to openpilot’s comma two. This Android device runs several background processes (~20 in total), that all communicate with each other and coordinate their actions.
All messages to and from the panda are managed by the boardd background process. boardd publishes these messages for other processes to use.
radard is listening closely to the messages boardd publishes, and will notice a message from the car’s radar system.
radard combines the radar CAN message published by boardd with data published by modeld (see the next section) and publishes a radarState message, which contains information such as the lead car distance.
This radarState message is then picked up by plannerd.
plannerd’s responsibility includes, as the name already conveys, planning the path the car needs to take.
It publishes this path, which can then be consumed by other processes.
The final process involved in this scenario is controlsd. Remember our little pseudo-code loop at the beginning of this post? That while loop is implemented almost verbatim in controlsd. controlsd converts the path published by plannerd into actual CAN messages, and does so in a car model-agnostic way. This is an important detail, because openpilot aims to support as many cars as possible, and having controlsd use interfaces instead of concrete implementations facilitates this vision. Adding support for new car models mainly deals with implementing new concrete implementations of the interfaces that controlsd uses.
Finally, controlsd sends the CAN messages back to boardd, which then writes them to the car’s CAN bus via the panda.
Scenario 2: Direction changes/road curve
Even highways have curves. How does openpilot sense line markers and act upon curves? Let’s investigate.
The starting point for our analysis this time is not boardd, but camerad. camerad, on the surface, is a very simple process with the only responsibility of publishing video frames from the back- and front facing cameras. These frames can then be consumed by other processes.
One process that is particularly interested in these frames is modeld. modeld transforms the camera frames using its machine learning model and publishes the result.
From this point on, the same processes are involved as in scenario 1. Namely, plannerd watches modeld’s output and incorporates it into its path planning. plannerd emits a steering wheel torque change encoded as a CAN message, which is then picked up by boardd and sent to the car’s CAN bus.
Infrastructure Components
In the above two scenarios we visited arguably openpilot’s most important processes. They are, however, not the only components within openpilot’s ecosystem.
Other components not directly related to core functionality aren’t that interesting, so we won’t spend many words on them:
- A collection of bash scripts is used to remotely pull and install new releases.
- Additional APK files to be installed by the user are located in the APK folder.
- Phonelibs contains libraries used on the Comma Two for communication with Android.
- Pyextra contains library-like functionality used by multiple components, including explicit exception messages.
Putting it together with code
Given the architectural outline above, we can look into the process of implementing it. So, put yourself in the shoes of a software architect for an autonomous driving system and think about the requirements that the system must adhere to:
- Atomic (Chapter 6.3) when it comes to signal handling. Because we deal with data that eventually physically moves the car, ambiguous instructions are intolerable.
- Compatible and extensible. Since the vision of comma.ai includes offering support for all popular cars, the code should also be designed for this.
- Universal. When your product is reliant on the open-source community, it helps when common ideas from software design are applied.
- Modular (Chapter 3.5). When changing or improving certain parts in your system, you do not want to touch the whole codebase. Additionally, modularity allows the separate modules to be tested independently and allows the use of multiple programming languages or protocols.
Openpilot possesses these requirements and provides us with nice examples of implemented design patterns, the most noteworthy to shed additional light on is publish and subscribe. This pattern plays a fundamental role in the autonomous driving system and enforces all things listed in the bullet list above. Briefly said, publish and subscribe is a system to orchestrate message passing between different software systems or components. The publishers only send, while the subscriber solely receives messages from the publishers that it is subscribed to.
Pub-Sub is particularly useful when an application asynchronously communicates with other applications that are not necessarily implemented in the same language and executed on the same platform or system. Moreover, within each component it allows for cherry-picking from the available publishers. This ensures that critical information only resides in places where it is of vital importance and introduces extensibility.
Extensibility in general
Next to the publish and subscribe pattern, openpilot has embraced other best practices from software engineering to allow for compatibility and flexibility. Examples include the use of base classes and interfaces. We can relate these phenomena to the product vision that aims to provide a distributed decentralized self driving car platform that is built and maintained by a community. Zooming out a bit and looking from a deployment perspective; cereal, opendbc and panda are becoming standalone projects in 2020. Together with the newly proposed development flow this should make it very interesting for people from the open-source community to contribute and create a system in which quality and community are keywords.
Trade-offs
We have seen some of the functional properties of the system, now we will take a look at some non-functional properties and their trade-offs.
Performance vs Privacy
George Hotz mentioned in a talk he gave in June 2019 that he believes that “The definition of driving is what people do when they drive”, implying that a driving assistant should be based on data provided by drivers. As mentioned and seen in the architecture diagram, one of the key parts of the system is the driving model, modeld. Because the driving model plays a vital part in the system it needs to be accurate and consistent, in order to prevent potential accidents from happening. The data needed for the model comes directly from drivers that use the openpilot system in their car, which brings up the question of data privacy. Some people might not want their car data to go to comma.ai. However at comma.ai they are very clear about data privacy, if you make use of their system, you give them the consent to use all the data generated while driving, which was also said by George Hotz in the aforementioned talk. Thus, they made a trade-off between model performance and data privacy in which they value the performance and accuracy over the privacy of the drivers.
Compatibility vs Maintainability
As mentioned near the end of scenario 1, openpilot aims to support as many cars as possible. Therefore building the system in such a way that it will be compatible with all these different cars and models is very important. As seen in the architecture diagram, and mentioned in scenario 1, openpilot deals with all these different cars and models by creating a new implementation of the interface used by controlsd. However, by creating all these files it also means that they need to be maintained separately. With the ever-growing number of openpilot supported cars, this means that eventually they need to maintain hundreds if not thousands of these interface implementations. Thus meaning that the company chooses to make a trade-off between compatibility and maintainability, by creating a system that has high compatibility, but in return loses some maintainability.
Bringing it all together
What started out as a simple while-loop ended up in a journey across processes, modules and design principles. We saw how pub-sub creates a modular, extensible design. We visited the trade-offs that developers made over the years, and their implications.
openpilot is a uniquely complex project, that aims to tackle a uniquely complex problem.